Track 1: Software Analytics
PhD Candidate: Elvan KulaTrack leader: Georgios Gousios, Arie van Deursen
The research area of software analytics seeks to leverage data collected from software engineering processes to improve the effectiveness and efficiency of these processes. Data collected for these purposes include issues, log data, source code repositories, epic descriptions, etc. Thanks to the abundance of data, it becomes increasingly viable to apply machine learning techniques (e.g., random forests, support vector machines, neural networks) to use historic development information to support current development activities.
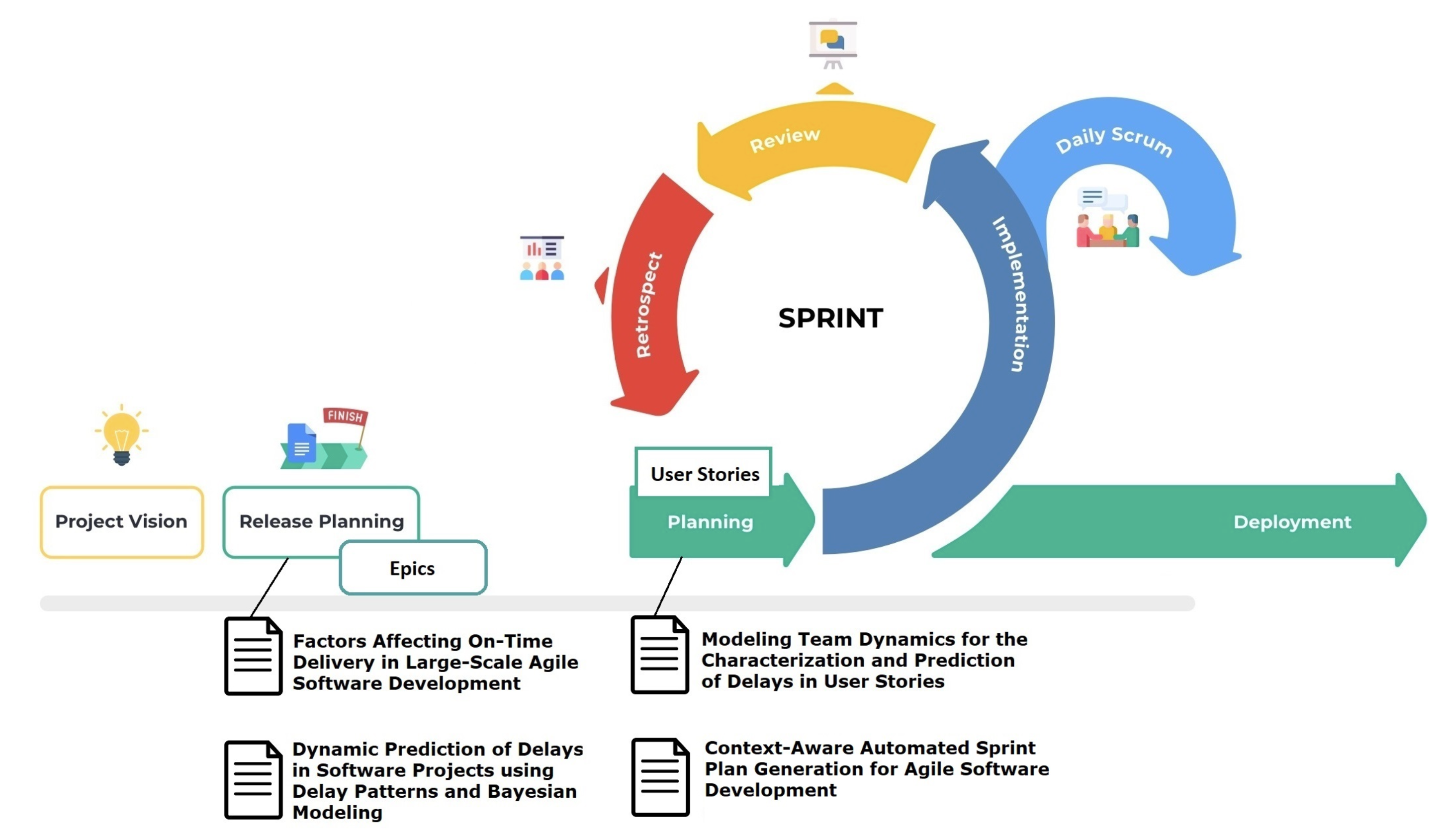
In the ING context, this is particularly relevant for the over 600 teams involved in software development. A key concern is epic predictability and epic delay which have been addressed within this track. Results include
- The identification of delay factors in epics;
- A novel approach to predict epic delay dynamically;
- A novel model of team dynamics to support the prediction of delays of user stories;
- An new optimization-based approach to plan generation for agile teams.
The results have been presented at top conferences and journals in the area of software engineering, and have yielded an ACM SIGSOFT Distinguished Paper Award at the prestigious Automated Software Engineering conference. All results have been developed on ING data directly, and have been shown to be effective in an ING context. The results are collectively described in the dissertation of PhD candidate Elvan Kula (defense date: April 2025).
Selected publications:
-
Elvan Kula. Modeling Effort Estimation and Planning in Large-Scale Agile Software Development. PhD thesis, Delft University of Technology, April 2025 (pdf).
-
Elvan Kula, Arie van Deursen, Georgios Gousios. Context-Aware Automated Sprint Plan Generation for Agile Software Development. Proceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering. 2024. 🏆 ACM SIGSOFT Distinguished Paper Award. (DOI).
-
Elvan Kula, Eric Greuter, Arie van Deursen, Georgios Gousios: Dynamic Prediction of Delays in Software Projects Using Delay Patterns and Bayesian Modeling. FSE 2023 (preprint).
-
Elvan Kula, Eric Greuter, Arie van Deursen, Georgios Gousios: Factors Affecting On-Time Delivery in Large-Scale Agile Software Development. IEEE Trans. Software Eng. 48(9): 3573-3592, 2022 (open access link).
-
Elvan Kula, Arie van Deursen, Georgios Gousios: Modeling Team Dynamics for the Characterization and Prediction of Delays in User Stories. ASE 2021: 991-1002 (preprint).
-
Hennie Huijgens, Ayushi Rastogi, Ernst Mulders, Georgios Gousios, Arie van Deursen: Questions for data scientists in software engineering: a replication. ESEC/SIGSOFT FSE 2020: 568-579 (preprint).
-
Elvan Kula, Ayushi Rastogi, Hennie Huijgens, Arie van Deursen, Georgios Gousios: Releasing fast and slow: an exploratory case study at ING. ESEC/SIGSOFT FSE 2019: 785-795 (preprint).
-
Hennie Huijgens, Eric Greuter, Jerry Brons, Evert A. van Doorn, Ioannis Papadopoulos, Francisco Morales Martinez, Mauricio Finavaro Aniche, Otto Visser, Arie van Deursen: Factors affecting cloud infra-service development lead times: a case study at ING. ICSE (SEIP) 2019: 233-242 (preprint).
-
Hennie Huijgens, Davide Spadini, Dick Stevens, Niels Visser, Arie van Deursen: Software analytics in continuous delivery: a case study on success factors. ESEM 2018: 25:1-25:10 (preprint).
Other Activities
-
Arie van Deursen. Explainable Fintech: A Trans-Disciplinary Perspective. Keynote address, F3C25, the FutureFintech Federated Conference, March, 2025, Luxembourg. Slides: https://speakerdeck.com/avandeursen/explainable-fintech-a-transdisciplinary-perspective
-
Arie van Deursen. Valuable Software Engineering. Keynote address, MODELS 2024, Linz, Austria. Slides: https://speakerdeck.com/avandeursen/valuable-software-engineering
-
Arie van Deursen. Explainable Software Engineering. Keynote address at Bit & Chips, October 2023, Eindhoven, The Netherlands. Slides: https://speakerdeck.com/avandeursen/explainable-software-engineering
-
Arie van Deursen. FinTech: A Fertile Ground for Software Engineering Research. Presentation at the Interdisciplinary Centre for Security, Reliability and Trust (SnT), Luxembourg. June 2023.
