
PyTorch
By Ziyu Bao, Tian Tian, Yuanhao Xie, Zhao Yin from TU Delft.

Abstract
PyTorch is an open-source deep learning platform. In this report, we systematically analyzed it and obtained a structural view of its architecture. Analysis include its stakeholders, context view, development view, technical debt and deployment view.
Table of Contents
- Introduction
- Stakeholder Analysis
- Context View
- Development View
- Technical Debt
- Deployment View
- Conclusion
- References
- Appendix
Introduction
PyTorch is created and developed primarily by Facebook’s artificial intelligence group as an open-source deep learning architecture that provides a seamless path from research prototyping to production deployment. Everyone could use it to build its own customized neural networks or perform fast matrix operations on GPUs using the torch component. In this report, we want to systematically analyze its architecture.
Stakeholder Analysis
In this section, we will perform a PR analysis, identify the stakeholders and other kinds of stakeholders and identify integrators of Pytorch. We also present a Power vs. Interest grid and give an analysis of the figure.
PR Analysis
A codification process is in the appendix.
The author of the pull request creates a new functionality and shows the usage to whom it will concern. After the showcase, two main members of PyTorch have a lot of reviews, suggestions, technical questions and vital decisions in the conversations of the pull request which are basically about, in the code level, improvements, small bugs, big issues, abstract representations (e.g., one attribute should morally be included in another class) and connections with other parts of PyTorch. This issue-solution pattern as an atom or a routine circle is repeated many times before a final approvement is reached to ensure the whole process trackable and efficient. Experienced reviewers largely influence the enhancement and complement of the new functionality or the code to be specific.
Looking over all the conversations during which the code base of the original pull request gets improved and reconstructed, I notice that the members of PyTorch expect to see this new change thus the whole process is going quite fast and active. Meanwhile, the author is able to fully understand the suggestions, follows them strictly and comments every subtle change to make things clear, which saves quite a lot of time. With efficient and extensive cooperative efforts of the author and reviewers, the pull request becomes good enough and is naturally ready to merge.
After this kind of laborious analysis, we are quite sure what it is about and what is going on within this specific pull request. Besides, whether a pull request would be accepted depends a lot on the main developers’ perspective and its external connection with the interest of the open source project.
Stakeholders
According to stakeholders in Chapter 9 of Rozanski and Woods 1, we classified stakeholders into 11 different types. Table below introduces each type of stakeholders in detail, including a short summary and description.
| Type | Stakeholders | Summary | Description |
|---|---|---|---|
| Developers | Core developers(@fmassa,@apaszke, etc.) and contributors | Developers are the largest group of all stakeholders. Anyone involved in the software development can be seen as a developer. | @apaszke @fmassa are core developers. They are almost involved in every pull request. They are also responsible for merging the accpted pull requests. Up to now, there are 994 contributors who developed Pytorch on GitHub, including aspects like system design and code writing. |
| Acquirers | Organizations, research institutes | Acquirers oversee the procurement of the software and give the financial support. This kind of stakeholders usually is the most important part, because they can control the future roadmap of the software. | Facebook is the main financial supporter of PyTorch. In addition, Facebook, the Idiap Research Institute, New York University (NYU) and NEC Labs America hold copyrights of Pytorch. |
| Assessors | Developers, internal assessment department and external legal entities | Assessors supervise whether the development or test of the software meet the legal regulations. | Developers, in addition to developing the system, also assess if the system is confronted to standards and legal regulations. There are also external legal departments that always check the system’s legal compliance. |
| Communicators | Community participants, teachers | Communicators manage to explain the system to other stakeholders. | GitHub, PyTorchDiscuss and Slack are three official communities for stakeholders to ask questions and answer questions. In addition, PyTorch tutorials can be found in many webstations. |
| Maintainers | Some developers | Maintainers guarantee the normal operating of the system. | Some developers are in charge of the daily maintenance of Pytorch on GitHub. @ezyang is one of the maintainers. He has claimed a method to enable non-facebook employees to get their pull requests merged. |
| Production engineers | @Yinghai Lu and @Duc Ngo and other engineers | Production engineers are in charge of the deployment of hardware and software environments in the system. | @Yinghai Lu and @Duc Ngo are software engineers of PyTorch. They take charge of tensors and dynamic neural networks in python with strong GPU acceleration. |
| Suppliers | Libraries, GitHub | Suppliers provide the hardware, software, or infrastructure which the system needs while developing. | PyTorch has a rich ecosystem of tools and libraries to support it. Alibaba (Arena): Alibaba cloud’s deep learning solution-Arena supports the PyTorch frameworks. fastai, Flair, Glow, GPyTorch, Horovod, Ignite, ParlAi, PyroAi, TensorLy and Translate are all suppliers providing services for PyTorch. What’s more, GitHub is the main supplier for its development. |
| Support staff | Developers, Teachers, Customer service | Support staff (including technical support, customer service, etc.) support the product or system when it runs. | Developers have the right to give technical support on commnuities. Teachers help users for running the system. Customer services of PyTorch provide service for solving the problems from users. |
| System administrators | Main engineers @Yinghai Lu and @Duc Ngo and other engineers, core developers | System administrators coordinate the overall development. | The main engineers take charge of the operation of PyTorch. Core developers control the evolution and development of different projects on PyTorch. |
| Testers | Developers @MlWoo,etc. | Testers systematically test the system to determine if it is suitable for deployment and use. | One of the testers is @MlWoo. He benchmarked the functionality of CNN of PyTorch on different mainstream CPU platforms |
| Users | All developers and some organizations using PyTorch | Users experience and use Pytorch and have the right to give feedback. Developers also use Pytorch. | AllenNLP is an open-source research library built on PyTorch for designing and evaluating deep learning for NLP. ELF is a platform for game research that allows developers to test and train their algorithms in various game environments. Stanford University uses Pytorch on their researches of new algorithmic approaches. Udacity uses PyTorch to educate the next wave of AI innovators. Salesforce uses PyTorch to push the state of the art in NLP and Multi-task learning. |
Going beyond Rozanski and Woods classification
Competitors: Competitors can be one of the stakeholders that concern the development of Pytorch. In this case, TensorFlow is a competitor. It is based on Theano and developed by Google. Since Pytorch releases, Pytorch obtains lots of attention and is considered to be a better version than Tensorflow.
Founders: Founders can be considered as the first developers of a software. In our project, PyTorch is created by an AI research team of Facebook. The original authors include Adam Paszke, Sam Gross, Soumith Chintala, Gregory Chanan. They used the torch framework and implemented it on Python environment.
Integrators/Reviewers in PyTorch
The core developers such as @apaszke @fmassa are integrators. They are architects of PyTorch. Their challenges in developing Pytorch are checking all the pull requests and make sure only the pull requests which pass the integration checks can be merged. In this way, the project can keep stable. The integrators almost involve in every pull requests. They use automatic code checking to reduce the review workload. If there are mistakes in the pull requests, they ask the contributors to explain and they discuss with other integrators. The integrators are also responsible for providing more context to a particular issue if people would like to implement a feature or bug-fix for an outstanding issue and need more information.
Contact Persons
Pytorch has many developers who are the main members of the team. We want to contact them to better understand Pytorch. We just went to their github pages and find their email addresses if they have provided them. We also chose to leave a comment in the discussion they involved to contact them. Here is a list that we contacted: Zeming Lin, Yuandong Tian and Edward Yang.
Power vs Interest Grid
The figure below shows the Power & Interest grid.
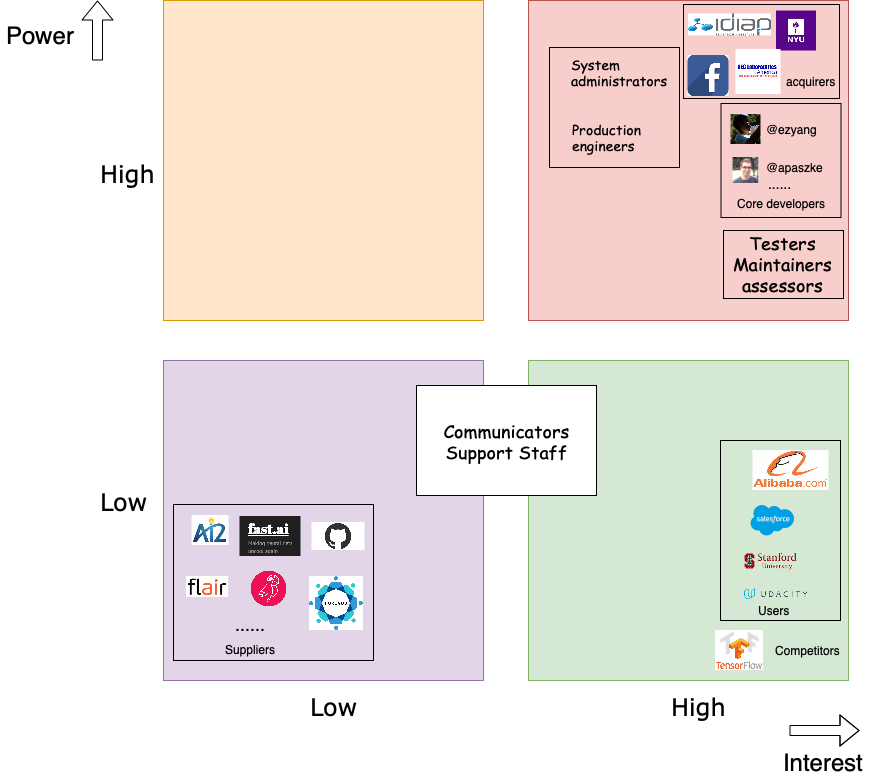
High power and high interest: Core developers have the right to accept project modifications but not like administrators and production engineers who have more power. Testers, maintainers, and assessors take responsibility of testing the system, managing the evolution, and overseeing the system’s conformance to standard, respectively. Therefore, they have a slightly lower power compared with core developers. Testers, maintainers and assessors have the same level interest as core developers. Acquirers oversee the procurement of the system and give the financial support. Within them, Facebook is the founder. They usually are the most important part, as they can control the future roadmap of the software. Therefore, they have the highest interest and power.
Low power and high interest: Users use PyTorch and cares about its development. But they do not have high power compared with stakeholders described above. Competitors do not have power on Pytorch, but they are highly interested in every detail of Pytorch.
Low power and low interest: Suppliers have their services used by Pytorch but they do not necessarily care about Pytorch and they do not have power in Pytorch either.
Communicators and Support Staff: Communicators mainly focus on creating documentation and training material to explain PyTorch. In general, they do not have other power. Support Staff help users to run the system. They have no decision power. Therefore, both of them are mildly interested in PyTorch with relatively low power.
Stakeholder Analysis conclusion
In conclusion, we make a brief analysis on a pull request. We then introduce many types of stakeholders and specify what they concern and where they are involved in Pytorch. There are also two types of stakeholders beyond R&W’s classification which are founders and competitors. They have different interest and power to the project. Integrators are identified above. Their challenges and merging strategy are discussed. At last, we prensent a Power&Interest of the stakeholders of Pytorch.
Context view
This session describes the scope and responsibilities of Pytorch and its relationships with external entities. The interface with external entities will be described in detail in a diagram.
System Scope and Responsibilities
Pytorch has its trace of development of its scope and responsibilties. In the Roadmap to Pytorch 1.0, the Pytorch team has described their thoughts on the scope of Pytorch 1.0 compared with Pytorch 0.2, 0.3 and 0.4. We can learn from their thoughts and define the scope and responsibilities of Pytorch as follows:
- Tensor computation (like NumPy) with strong GPU acceleration
- Deep neural networks built on a tape-based autograd system
- Support for wide AI uses
- Good for research and hackability
- Support efficient industry production at massive scale
- Support exporting models to Python-less environment
- Support debugging for exported models
- Support user-written C++ extensions
- Support for platforms of Caffe2 (iOS, Android, Raspbian, Tegra, etc) and will continue to expand various platforms support
Context Diagram
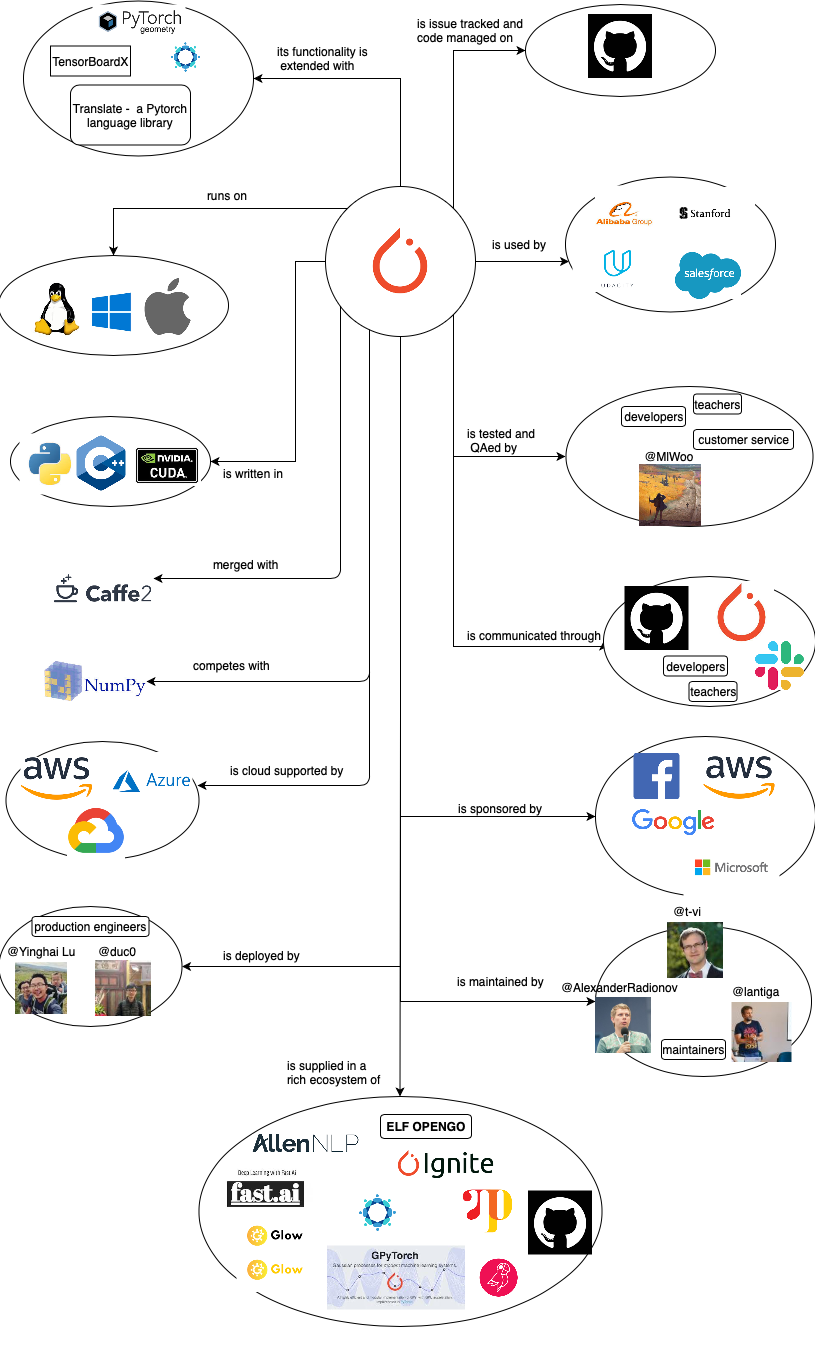
The context diagram shows interfaces of Pytorch with external entities. The external entity can be a person, an organization or a system that “implements, offers or uses services of Pytorch, or manages, provides or uses data of Pytorch” 1. The diagram presents the data/services transferring between external entities and Pytorch.
External Entities
External entities are examined in detail as follows:
-
Communication: Communications are mainly done in GitHub, PyTorchDiscuss and Slack. Communicators supply data to Pytorch in the form of conversational materials to be studied to help Pytorch improve.
-
Storage: AWS, Google and Microsoft all have provided support of their cloud platforms for data storage of PyTorch.
-
Tools: Horovod is a distributed training framework that can be used by PyTorch. Pytorch Geometry is a library of PyTorch for geometric computer vision. TensorBoardX is a visulization tool that can log events happening e.g. during training of a neural network. Translate extends PyTorch functionality to train for machine translation models.
-
Users: PyTorch is used from industry to acedemia. When it is used in industry, it is used as part of the core business of companies, like Alibaba or Salesforce, to support deep learning framework. When it is used in academia, PyTorch can support researches by providing new algorithmic approaches, like in Stanford University. These users in turn also provide feedback and data to Pytorch to train with, which makes them an external entity.
Development View
The development view of PyTorch describes its code structure and dependencies, build and configuration of deliverables, system-wide design constraints and system-wide standards to ensure technical integrity 1. We here analyze the module structure model, common design models and codeline model.
Module Structure Model
The main structure of PyTorch in a architectural view is shown in the figure below.
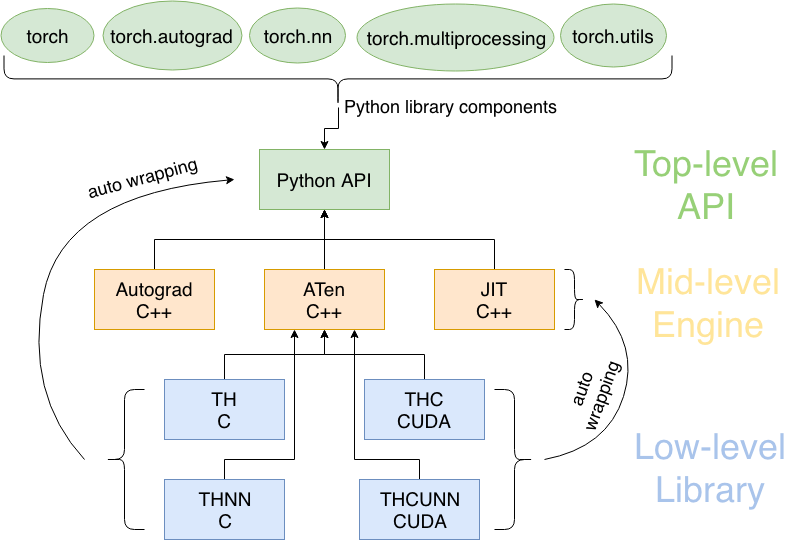 Pytorch Architecture. Inspired by 2
Pytorch Architecture. Inspired by 2
The top-level Python library of PyTorch (please refer to the following section) exposes easy-to-understand API for users to quickly perform operations on tersors, build and train a deep neural network. This library provides interface but doesn’t really execute the computations. Instead, it delivers this job down to its efficient computation engines written in C++.
These engines on the middle-level of module structure consist of autograd for computing DCG and providing auto-differentiation, JIT (just-in-time) compiler for optimizing computation steps that are traced, ATen as a C++ tensor library that wraps low-level C library for PyTorch (no autograd support).
The low-level C or CUDA library does almost all the intensive computations assigned by upper-level API. These libraries provide efficient data structures, the tensors (a.k.a. multi-dimensional arrays), for CPU and GPU (TH and THC, respectively), as well as stateless functions that implement neural network operations and kernels (THNN and THCUNN) or wrap-optimized libraries such as NVIDIA’s CuDNN 2.
ATen wraps those low-level libraries in C++ and then exposes to the high-level Python API. Similarly, the neural network function libraries (low-level) are automatically wrapped towards the engine and Python API (see the two curved arrows). In other words, the low-level libraries can be utilized not only by its standard wrapper ATen but also top-level Python APIs and mid-level engines. This kind of connection keeps the code loosely coupled, decreasing the overall complexity of the system and encouraging further development 2.
Component Overview
PyTorch as a libary consists of the following components (also see Figure 3 for the connection with the module structure):
- torch: a Tensor library like
NumPy, with strong GPU support 3. It contains data structures for multi-dimensional tensors, and defines many mathematical operations based on these tensors. Different from its analogueNumPy, all the data structures and tensor operations can be seamlessly performed from CPU to GPU which would accelerate the computation by a huge amount. - torch.autograd: a tape-based automatic differentiation library that supports all differentiable Tensor operations in
torch3. This functionality greatly differs PyTorch from other machine learning or deep learning frameworks like TensorFlow 4, Caffe 5 and CNTK 6 which require users to restart from scratch at beginning in order to change some minor behaviors of the neural network once created. While in PyTorch, a technique called reverse-mode auto-differentiation is adopted to facilitate differentiation process so that the computation graph is computed in the fly which leaves users more time to implement their ideas. - torch.nn: a neural networks library deeply integrated with autograd designed for maximum flexibility 3. This component or module in PyTorch provides a high-level functionality for us to build and train a deep neural network easily without pain. It contains many types of neural network layers like convolutional layers, recurrent layers, padding layers and normalization layers.
- torch.multiprocessing: Python multiprocessing, but with magical memory sharing of torch Tensors across processes. Useful for data loading and Hogwild training 3. This component wraps native Python multiprocessing module using shared memory to provide shared views on the same data in different processes.
- torch.utils: DataLoader, Trainer and other utility functions for convenience 3. It consists of five submodules -
torch.utils.bottleneckfor debugging bottlenecks in the program,torch.utils.checkpointfor checkpointing a model or part of the model and etc.
Common Design Model
This section uses a common design model to analyze how PyTorch tries to achieve its developmental approach.
Common processing
Common processing identifies tasks that benefit greatly from using a standard approach across all system elements.
Use of third-party libraries. PyTorch makes use of third-party libraries for build, doc generation, high-level operations and etc. Some of them are:
- python-future: a missing compatibility layer between Python 2 and Python 3 7.
- numpy: a fundamental package needed for scientific computing with Python 8.
- pyyaml: a next generation YAML parser and emitter for Python 9.
- setuptools: a fully-featured, actively-maintained, and stable library designed to facilitate packaging Python projects 10.
- six: a Python 2 and 3 compatibility library that provides utility functions for smoothing over the differences between the Python versions with the goal of writing Python code that is compatible on both Python versions 11.
- typing: a Python library support for type hints.
- matplotlib: a Python 2D plotting library which produces publication-quality figures in a variety of hardcopy formats and interactive environments across platforms 12.
Documentation management. Well documented code benefits code readability, practical implementation and issue tracing. PyTorch uses Google style for formatting docstrings. Length of line inside docstrings block must be limited to 80 characters to fit into Jupyter documentation popups. For C++ documentation it uses Doxygen and then convert it to Sphinx via Breathe and Exhale 3.
Standard design approaches
Standard design approaches identifies how to deal with situations where implementations of a certain aspect of an element will have a system-wide impact.
API design standardization. (resource from 13) The essential unit of PyTorch is the Tensor. As the Tensor is used in Python for users but implemented in C, it needs API design to wrap it up so that user can interact with it from the Python shell. PyTorch first extends the Python interpreter by CPython’s framework to define a Tensor type that can be manipulated from Python. The formula for defining a new type is as follows: 1) create a struct that defines what the new object will contain and 2) define the type object for the type. Then PyTorch wraps the C libraries that actually define the Tensor’s properties and methods by CPython backend’s conventions. The Tensor.cpp file defines a “generic” Tensor and PyTorch uses it to generate Python objects for all the permutations of types (float, integer, double and etc.). PyTorch takes the custom YAML-formatted code and generates source code for each method by processing it through a series of steps using a number of plugins. Finally to generate a workable application, PyTorch takes a bunch of source/header files, libraries, and compilation directives to build an extension using Setuptools.
Contributing standardization. As PyTorch is an open source, everyone is free to contribute to the repository. In order to keep maintainability, reliability, and technical cohesion of the system, the PyTorch Governance (consisting of code maintainers, core developers and some other contributors) composed a contributing tutorial to standardize the design process. The tutorial provides useful guidelines for coding, parameter configuration, testing, writing documentation and all other tips and rules for qualified contribution.
Codeline Model
Source Code Structure
PyTorch has its code structure to make it easy for developers to locate the code they want to change. We show its main directory below while the full directory could be seen on here.

Build approach
For development build, PyTorch and its third-party frameworks are built using Python Setup tools. We need to specify the command parameters if only part of the components are required to rebuild Pytorch. For users build, both package managers - Anaconda and pip could be used to build the whole project.
Release process
PyTorch has released 21 versions since 2016. We divided them into three stages. At the beginning, Pytorch was busy with developing new functions, so it released a new version every month, or even twice a month. In the second stage, Pytorch tended to be stable, so it released nearly every two months. In the recent stage, Pytorch focused more on fixing existing bugs than developing new functions, so it released at a frequency lower than before.
Technical Debt
Technical debt reflects the implicit cost of choosing a simple solution instead of using a better method that takes a longer time. In this section, we first identify different forms of technical debts which include the keywords/tags, the complexity trend of the hotspot, code smell(temporal coupling and duplicated code), and bugs. We also list the methods to reduce or avoid these technical debts. Then, we discuss the testing debt. In the end, the evolution of technical debt is explained.
Identifying Technical debt
The tools we used to identify the technical debts are listed below:
| Name of tool | Usage |
|---|---|
| CodeScene | Identifying hotspot, complexity trends of the hotspot, and temporal coupling |
| Github-grep | Finding keywords like TODO, FIXME and XXX |
| SonarQube | Identifying duplications and finding bugs |
The reasons we decided to use these tools are:
- CodeScene is an easily operated tool and has several intuitively functions to show the code structure and point out some parts that really matter, for example, the hotspots. We choose three functions to identify hotspot, complexity trends and temporal coupling.
- Github-grep is a tool of Git to search everything you want in the code. We used this tool to find all three keywords:
TODO,FIXMEandXXX. - SonarQube is a powerful code quality management tool. It detects the code quality in the following aspects: bugs, vulnerabilities, code smells, code coverage and duplications. Since some of those aspects we have used
codesceneto analyze, we mainly analyze the duplications and the bugs by using SonarQube.
Keywords/tags
Keywords/tags indicates the technical debts which the developer noticed but did not fix. As along with the accumulation of tags, some of them may be forgotten, or become bugs 14. Furthermore, these keywords may clutter the code and have negative effects on code comprehension 14. This large amount of technical debts may make developers difficult to comprehend the code.
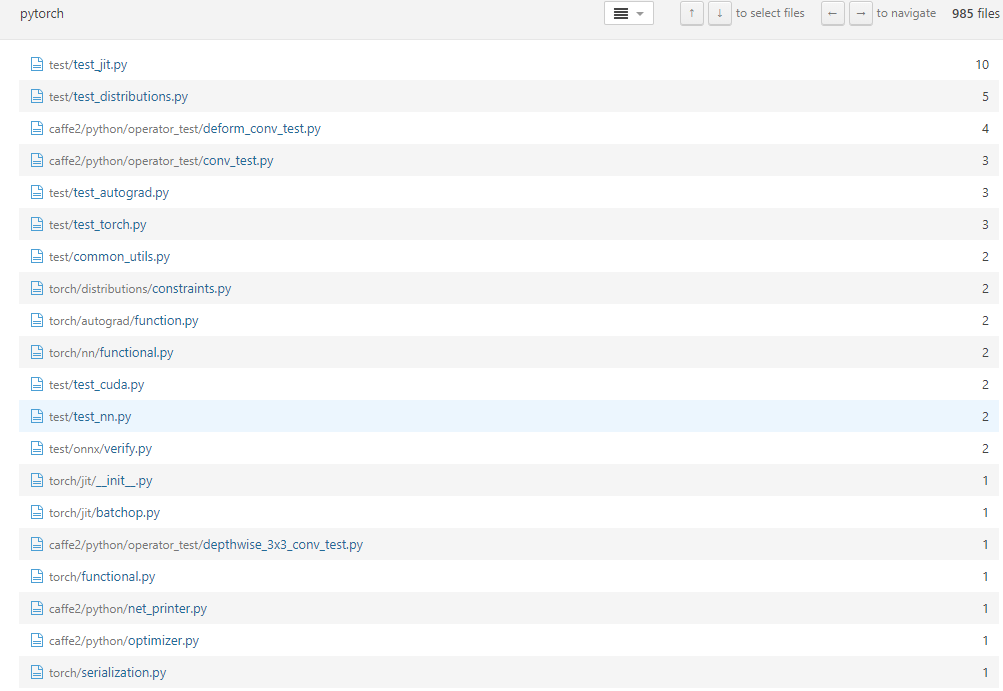
We analyzed three kinds of keywords/tags “TODO”s, “FIXME”s and “XXX”s in PyTorch. We found that even though the tags have different names, but their contents are quite similar. We found 1098 “TODO”s. They are almost everywhere in PyTorch. 432 “TODO”s are in caffe2. There are 118 “FIXME”s, they are mainly in aten, caffe2, test, torch. There are 119 “XXX”s identified, 72 of them are in the main PyTorch component-torch. Some of the tags mentions who will fix it, none of them mentions when they will be fixed. Following are the examples:

Complexity trend of hotspots
The reason why we analyze the hotspots is that the code with the high technical debt can be found by analyzing the ‘hotspot’ 15. Hotspots are those large, complex code which the developers have to work often with. We usedCodescene to analyze the hotspots.
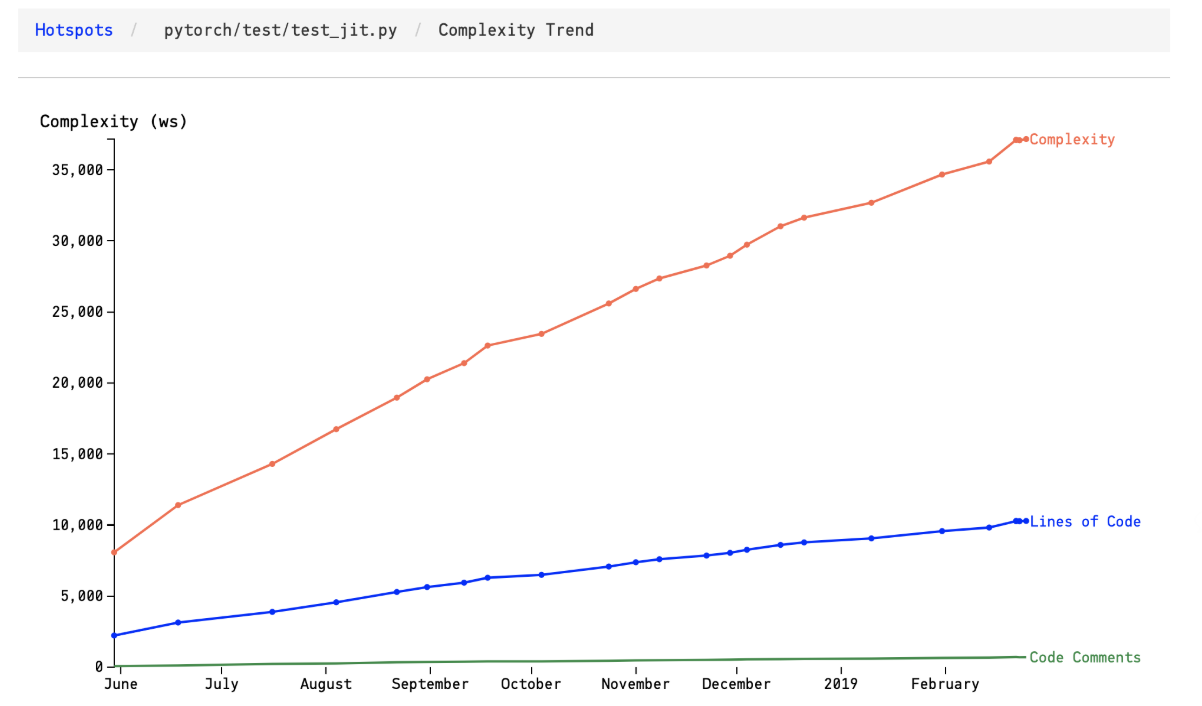
As shown in the figure below, each blue circle represents a package in the code, and the red dots are the hotspots 15.
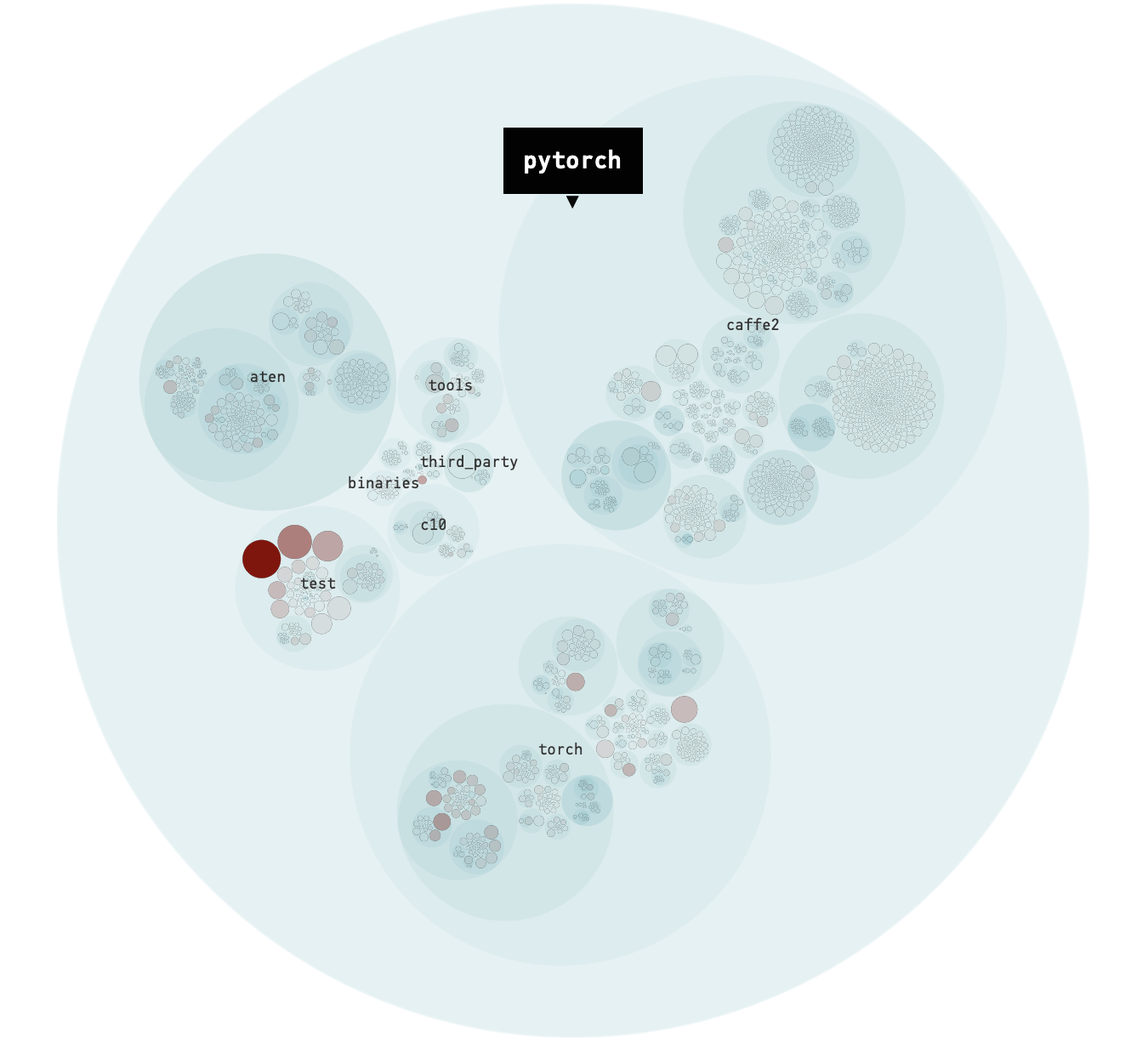
Complexity trends denote how do the hotspots get more complicated over time. The hotspot with fast-growing complexity should be prioritized for refactoring to reduces the risk of technical debt. Otherwise, as soon as the complexity becomes unmanageable, the code modifications become really difficult 15.
As shown in the figure below, the complexity trend of hotspot pytorch/test/test_jit.py grows rapidly since June 2018. This accumulating complexity is a sign that the hotspot needs refactoring 16 to reduce the risk of technical debt.
Temporal coupling
Temporal coupling is a kind of codesmell. The large codebases with multiple developers may lead to technical debt. Even though at the beginning of development, developers separate the modules on purpose, the couplings may still form during development. The couplings among different modules lead to rigid system design and the difficulty of extending the features 17. Temporal coupling indicates how two or more modules change together over time. It can be obtained by calculating how often a module changes together with other modules. We used Codescene to visualize the temporal coupling.
In the figure below, the lines that the modules which are modified together. The thicker lines, the stronger of temporal coupling.

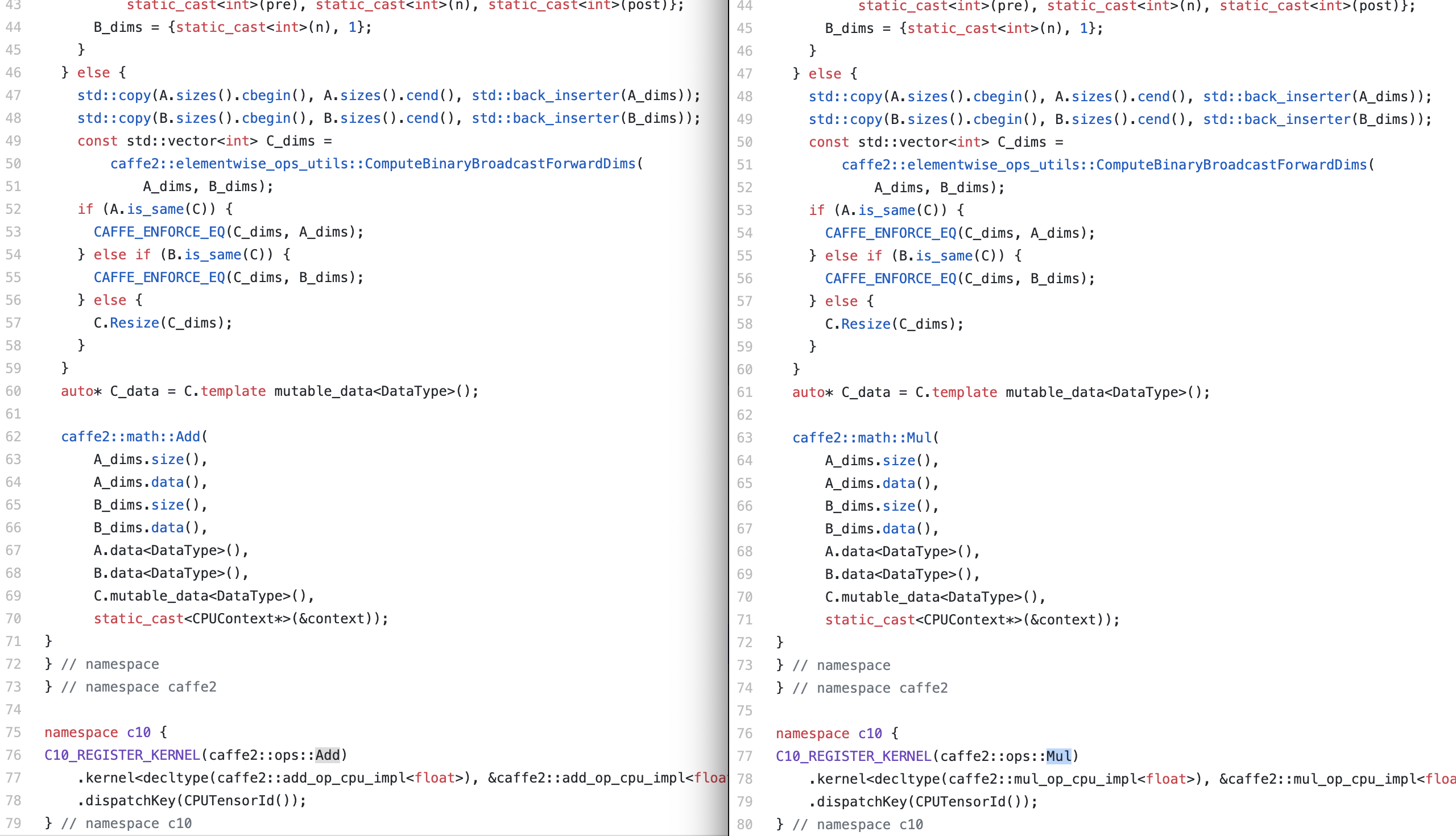
The coupling degrees of the pairs shown in the table in the right of the Figure are quite strong. For example, the coupling degrees of the third pairs are 95%. It means that 95% chance of changing one file results in a change in another file. The temporal coupling sometimes suggests a refactoring. As you can see the coupling degrees of the first pairs are 100%. The figure below shows the code of add_cpu.cc and mul_cpu.cc. These two files are more like copy-paste work.
Duplications and existing bugs
To identify duplications and existing bugs, we utilized SonarQube.
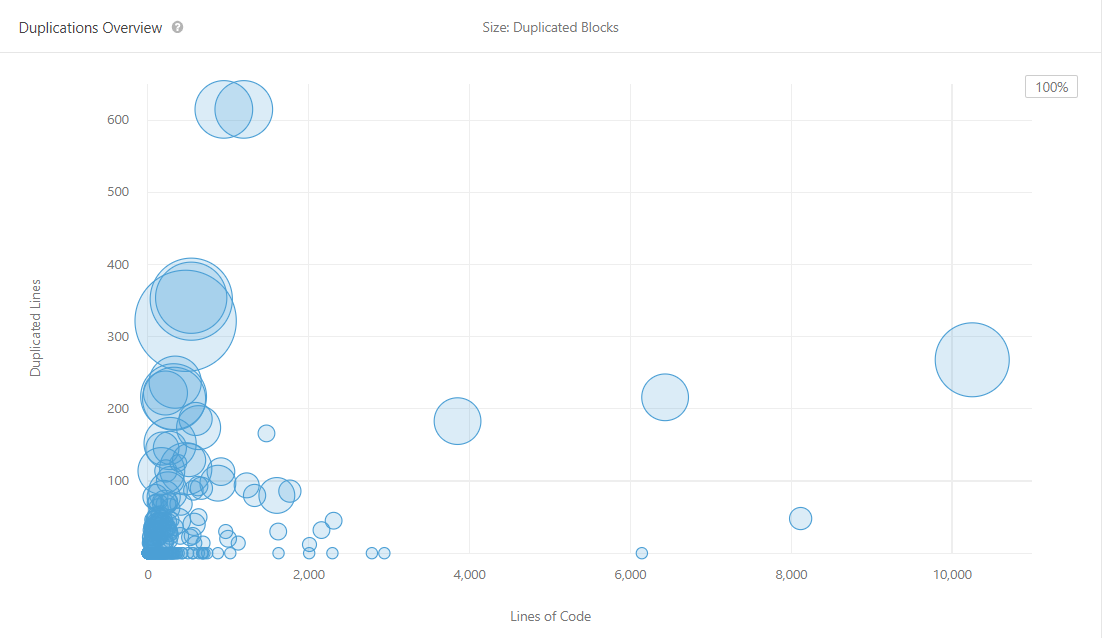
Duplicates: Duplicates illustrate those recurring code. It belongs to code smell which is the potential threat in software development. Developers should keep less duplicated code to make the code clean. The figure below shows all the duplicates in PyTorch. There are overall 3.6% duplicates. It should be noticed that the test files contain the most duplicates. In our analysis, test files need to test different cell but theoretically use the same way, so the codes look like the same.
Bugs: We also used SonarQube to find bugs in Pytorch. Bugs can lead to a really bad impact on system and developers should try their best to avoid creating bugs. In our cases, the tool detected 98 bugs in the current release. It is shown in the first figure below. The bugs identifed by SonarQube indicate almost the same problem as shown in the second figure below: Those codes contain the identical sub-expressions on both sides of operator “or”. This kind of codes were recognized as bugs. It should be noticed that those codes were written 2 years ago, which can be considered as a long-time debt. Those codes should be fixed for better developing.

Overview of the solutions
After the analysis, we came up with the solutions to reduce or solve the technical debts:
-
To reduce the technique debt casued by accumulation of the keywords, the progress of fixing the issues should be tracked. This can be done by appointing an issue tracker and ask developers to add more details in the keywords/tags, such as the name who is responsible for the issue, deadline.
-
The complexity trend of the hotspots should be tracked regularly, If the complexity trend increases sharply, the hotspot should be appropriately redesigned and refactored.
-
The code smell such as the temporal coupling and the duplicated code should be track. Extract the common part into a module remove the duplications.
Identifying Testing Debt
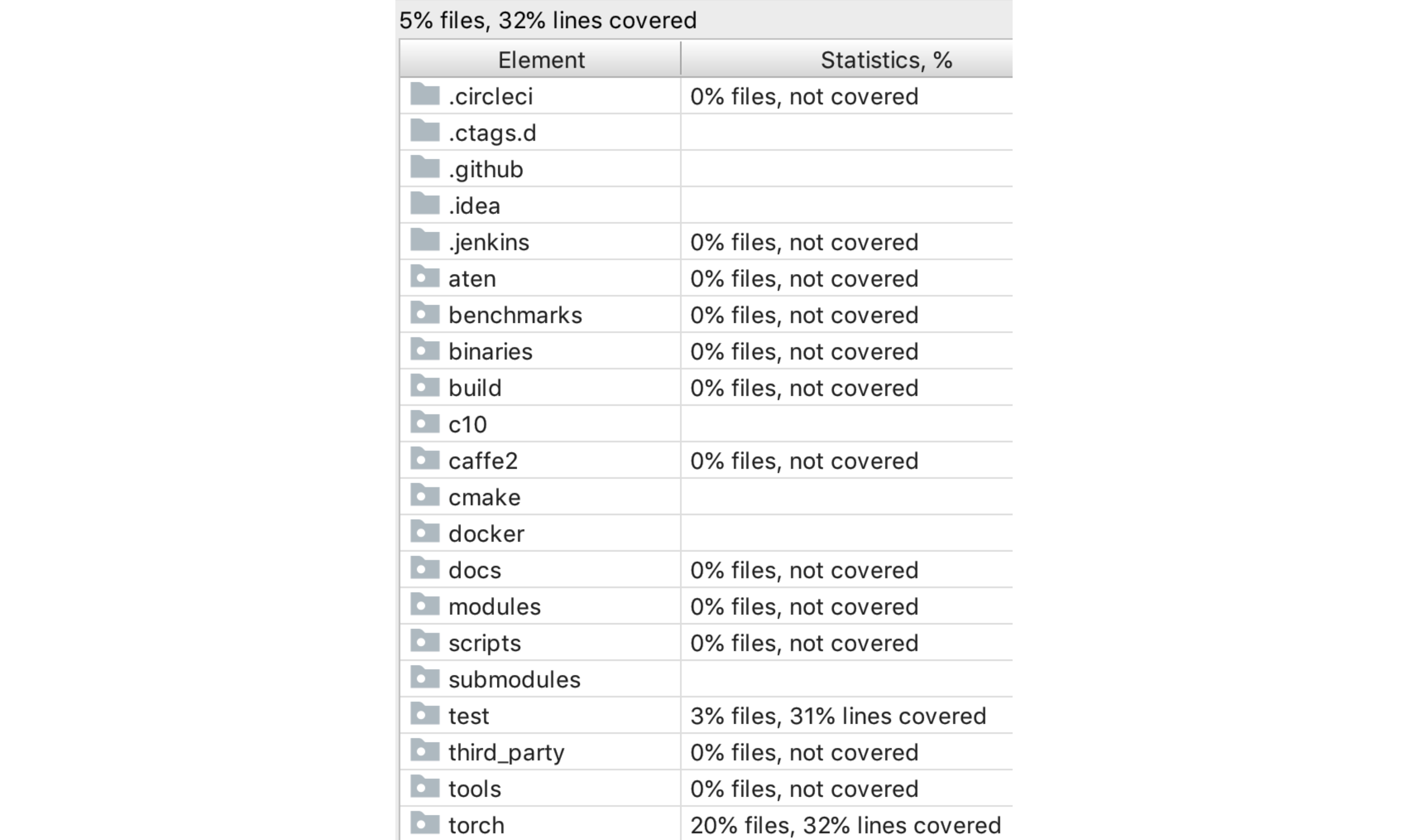
Testing debt exists due to the lack of testing or poor quality of testing. In this section, we analyze the testing debt of PyTorch.
By using a Python IDE - PyCharm, we get a detailed test coverage showing the files coverage of the whole project and lines coverage of every single Python file (see the figure above). Only 5% files and 32% lines are covered which are quite low. The reasons are two folds. One is that the tests (such as GPU test and distribution test) we run are not complete and the other one is that files in directories (e.g., aten, c10) are in C/C++ which could not be included.
Despite these exceptions, the test coverage is still not enough for such a widely used open source project. We can see that the torch module is coveraged due to it is the core module that currently being used frequently. Caffe2 and some other modules are not covered since they are rather complicated or too old, developers did not concern more on those modules. Thus, those files that not being test should be seen as test debt.
The evolution of Technical Debt
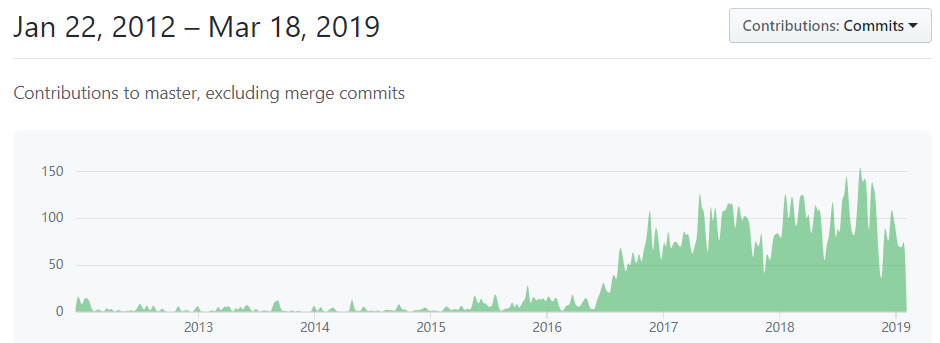
Since Pytorch was the next generation products of torch, it was developed officially since 2016. Pytorch was mainly developed on Github to control its different releases. As shown in the figure below, the contributions increased dramatically since 2016.
According to the releases showing on the Github, Pytorch has released several versions which from v0.1.1 to v1.0.1. We summarized those versions fixing bugs into a table. We can see the evolution of technical debt from this table. At the first six versions, Pytorch focus on developing new functions regardless of fixing bugs, we considered this stage as developing stage. Then, when the system gradually keep in stable, the developers begin bugs fixing. In the recent versions, since the early versions accumulated more technical debt and gradually effect the system daily running, developers focus on fixing bugs and check errors.
| Version | Bug Fix | Time |
|---|---|---|
| v0.1.1 | alpha-1 version, did not mention bugfix | Aug 24, 2016 |
| v0.1.2 | alpha-2 version, did not mention bugfix | Sep 1, 2016 |
| v0.1.3 | alpha-3 version, did not mention bugfix | Sep 16, 2016 |
| v0.1.4 | alpha-4 version, did not mention bugfix | Oct 3, 2016 |
| v0.1.5 | alpha-5 version, did not mention bugfix | Nov 8, 2016 |
| v0.1.6 | beta version, did not mention bugfix | Jan 21, 2017 |
| v0.1.7 | A bugfix release with small features: fixed 13 bugs | Jan 26, 2017 |
| v0.1.8 | A bugfix release with small features: fixed 10 bugs | Feb 3, 2017 |
| v0.1.9 | fixed 7 bugs | Feb 17, 2017 |
| v0.1.10 | fixed 19 bugs | Mar 5, 2017 |
| v0.1.11 | Bug fixed: torch: 6, autograd,nn,optim:13, other bugs: 2 | May 1, 2017 |
| v0.1.12 | fixed 24 bugs | May 3, 2017 |
| v0.2.0 | fixed 27 bugs | Aug 28, 2017 |
| v0.3.0 | Bug fixed: torch: 1, tensor: 26, sparse: 3 autograd: 7, nn: 19, optim: 1 | Dec 4, 2017 |
| v0.3.1 | Bug fixed: torch operators: 9, data: 8, autograd: 1, nn layers: 6, CUDA: 10, CPU: 1 | Feb 9, 2018 |
| v0.4.0 | Bug fixed: torch operators: 18, core: 7, autograd: 3, nn layers: 11, CUDA: 10 | May 30, 2018 |
| v0.4.1 | fix 25 bugs | Jul 26, 2018 |
| v1.0rc1 | serious bugs: 5, correctness bugs: 13, error check: 7 | Oct 2, 2018 |
| v1.0.0 | serious bugs: 11, correctness bugs: 29, error check: 13 | Dec 7, 2018 |
| v1.0.1 | serious bugs: 7, correctness bugs: 5, crashes bugs: 13 | Feb 7, 2019 |
Deployment View
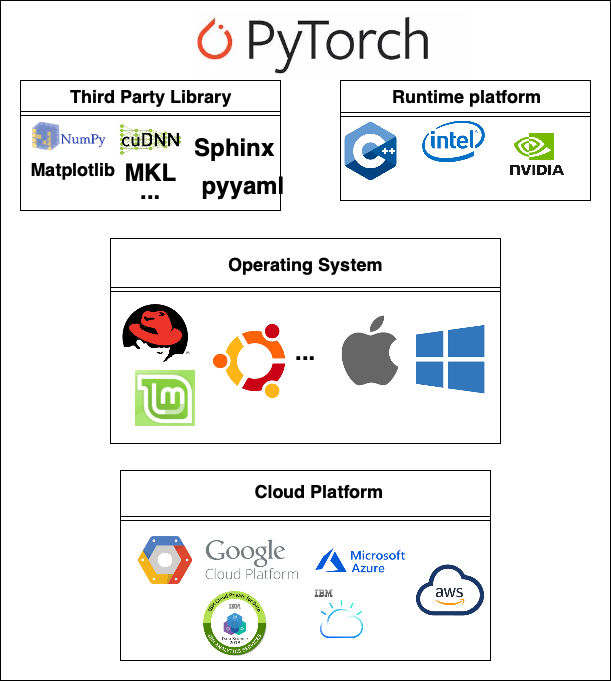
Deployment view determines the related environment to run the system. We will discuss the deployment view in the following passages and the figure below is the overall figure of the deployment view of Pytorch.
Third Party Library
Pytorch uses different libraries to develop its system. Those third-party libraries have been specifically introduced in section Development View. Those third parties including Numpy, Sphinx, pyyaml, CuDNN, MKL etc., form third-party system requirements for running Pytorch and support the daily operating of Pytorch.
Runtime platforms
Pytorch does not want to give up a Python frontend but a Python frontend cannot deal with, e.g., a multithreaded environment, so Pytorch employs a C++ frontend but it mimics a Python frontend closely. Pytorch has several backend modules intead of one. The modules rely heavily on linear algebra libraries like MKL for CPU and deep neural network libraries like CuDNN for GPU. Pytorch requires a 64-bit CPU. An Intel CPU is preferred because MKL is tuned for an Intel architecture. To benefit from GPU acceleration, Pytorch only works on NVIDIA GPUs, because it requires CUDA support. For high-demanding tasks in research or production, it is suggested to use an HPC platform or a cloud platform, e.g. AWS.
Operating systems
PyTorch can be installed and used in many types of operating systems.
- Linux: PyTorch 1.0 supports various Linux distributions that use glibc >= v2.17:
- Arch Linux, minimum version 2012-07-15
- CentOS, minimum version 7.3-1611Debian, minimum version 8.0
- Fedora, minimum version 24
- Mint, minimum version 14
- OpenSUSE, minimum version 42.1
- PCLinuxOS, minimum version 2014.7
- Slackware, minimum version 14.2
- Ubuntu, minimum version 13.04
- MacOS: PyTorch is supported on macOS 10.10 (Yosemite) or above. As MacOS does not has CUDA support building from binaries, it will not benefit from GPU accelaration.
- Windows: PyTorch is supported on the following Windows distributions:
- Windows 7 and greater; Recommended: Windows 10 and greater.
- Windows Server 2008 r2 and greater.
PyTorch on cloud
Cloud platforms provide powerful hardware and infrastructure for training and testing the PyTorch models. PyTorch offers following cloud installation options:
| Could Platform | Details |
|---|---|
| Microsoft Azure | Can choose between a GPU-based or a CPU-only instance of the Data Science Virtual Machine |
| Google Cloud Platform | On machine instances with access to one, four, or eight GPUs in specific regions or on containerized GPU-backed Jupyter notebooks |
| Amazon Cloud Platform | AWS Deep Learning AMI with optional NVIDIA GPU support |
| IBM Cloud Kubernetes cluster | On Kubernetes clusters on IBM Cloud |
| IBM Cloud data science and data management | Python environment with Jupyter and Spark |
Conclusion
With two months of analysis of Pytorch, we gain more insights of the whole Pytorch architecture. We analyze different perspectives and viewpoints of the project to understand more about the inner workings. Even though Pytorch is a recently-developed software, it already has a well-organized architecture. And we believe it will keep developing and develop more functions for deep learning frameworks.
References
Appendix
PR Analysis
Pull requests which are accepted
| Pull request | Lifetime | Components it touches | PR content and Related issues | Deprecate another pull request or not |
|---|---|---|---|---|
| Implement adaptive softmax awaiting response #5287 by @elanmart | After v0.4.0 | torch.nn(neural networks library which is integrated with autograd designed) |
This pr implements “Efficient softmax approximation for GPUs” which discussed in another pr #4659 | No |
| Implement adaptive softmax awaiting response #5287 by @elanmart | After v0.4.0 | torch.nn(a neural networks library deeply integrated with autograd designed for maximum flexibility) |
This pr implements “Efficient softmax approximation for GPUs” which discussed in another pr #4659 | No |
| Parallelize elementwise operation with openmp #2764 by @MlWoo | After v0.4.0 | Low-level tensor libraries for PyTorch(TorcH) | This pr parallelizes elementwise operation of discontiguous THTensor with openmp | No |
| Implement sum over multiple dimensions #6152 by@t-vi | After v0.3.1 | ATen C++ bindings | This pr implements summing over multiple dimensions as an ATen native function and fixed #2006 | No |
| Fixed non-determinate preprocessing on DataLoader #4640 by @AlexanderRadionov | After v0.3.1 | torch.utils DataLoader(Trainer and other utility functions for convenience) |
This pr adds ind_worker_queue parameter in DataLoader to solve the non-deterministic issue which happens when DataLoader is in multiprocessing mode | No |
| Introduce scopes during tracing #3016 by @lantiga | After v0.2.0 | Scope, IR (intermediate representation) and Tracing |
This pr introduced the scopes for group operations in the tracing IR | No |
Pull requests which are rejected
| Pull request | Lifetime | Components it touches | PR content and Related issues | Deprecate another pull request or not |
|---|---|---|---|---|
| Fixes errors #10765 by @peterjc123 | After v0.4.0 | ATen C++ bindings | Fixes errors when linking caffe2 statically related to issues #10746 and [#10902](https://github.com/pytorch/pytorch/issues/10902 | No |
| Low rank multivariate normal #8635 | After v0.4.0 | torch.distributions, torch.trtrs |
Implements low rank multivariate normal distribution where the covariance matrix has the from W @ W.T + D. |
No |
| [caffe2]seperate mkl, mklml, and mkldnn #12170 | After v0.4.1 | Caffe2 component of PyTorch and Docs. | 1. Remove avx2 support in mkldnn. 2. Seperate mkl, mklml, and mkldnn. 3. Fix convfusion test case | No |
| Checkpointing #4594 | After v0.3.0 | torch.autograd, torch.utils and Docs. |
Autograd container for trading compute for memory. | Be deprecated by pull request #6467. |
| Adding katex rendering of equations #8848 | After v0.4.0 | Docs, torch/functional and torch.nn |
This fixes issue #8529. 1. Adds Katex extension to conf.py and requirements.txt. 2. Fixes syntax differences in docs. 3. Should allow documentation pages to render faster |
No |
Codify pull-request “Introduce scopes during tracing” #3016
From Ziyu Bao:
| Comments Index | Code |
|---|---|
| 1 | Introduce scopes, not accepted |
| 2 | Try-finally suggested |
| 3 | Change from 1 to multiple variables |
| 4 | Choices to make strings interned kept |
| 5 | Capture module name |
| 6 | Context manager for scopes/try-finally |
| 7 | Args to __call__ in module are flattened (instead of _first_var); introduced a torch.jit.scope context manager |
| 8 | Tracing_state in try finally for later proper cleaning-up |
| 9 | Setstate, child name |
| 10 | Remove if scope.empty in pushscope |
| 11 | Remove if the value is not none |
| 12 | Context manager activated only when tracing to reduce cost |
| 13 | Module name wasn’t gotten right, fixed |
| 14 | Printing of scope printed only if defined |
| 15 | Fixed scopes for the ONNX pass |
| 16 | Trying to merge |
| 17 | Cannot share common subtries between tries and not needed |
| 18 | Appeal to merge, discussion on scope stability |
| 19 | Add underscores, others are exposed on .torch namespace |
| 20 | Use unique_ptr safely |
| 21 | Raise an error if it can’t pop |
| 22 | Return scope name in scope class |
| 23 | Fix numerous small issues |
| 24 | Define jit in the module and attach the module to tracing |
| 25 | Activate dynamic attributes on TracingStat; manage a stack per trace |
| 27 | Build finished |
| 28 | Double check: Scope ownership scheme |
| 29 | Merged |
From Zhao Yin:
| Comments Index | Code |
|---|---|
| 1 | Usage showed |
| 2 | Small advice to use try-finally. |
| 3 | Technical advice about function usage. |
| 4 | Add name as the attribute to the module. |
| 5 | Add context managet to handle the scope. |
| 6 | Integration of advice above. |
| 7 | Cope with field missing after adding the name. |
| 8 | Remove passing an empty string to the decorator. |
| 9 | Remove redundant condition check. |
| 10 | Remove context when nothing is tracing. |
| 11 | Fix $O(n^2)$ to $O(n)$ of loading module tree. |
| 12 | Fix scopes for the ONNX pass. |
| 13 | Wait for autograd PR because it changes JIT infra. |
| 14 | This PR get rebased on the new master. |
| 15 | Make notes that different Graph can’t share portions of the trie. |
| 16 | Good enough, need to merge. |
| 17 | Two concerns: backward tracing with the scope not working and a “scope” is morally a property of the tracer. |
| 18 | Clarifications for the two concerns: making scope inexpensive and a Graph node needs to hold information. |
| 19 | State that the scopes are stable if name registered in Module is stable. |
| 20 | Add an underscore and leave others exposed to torch.. |
| 21 | Change pointer type for the root, scope, and children. |
| 22 | Raise error when can’t pop. |
| 23 | Question (with the answer of not using the flat list of scope) about reversing. |
| 24 | Put string representation inside scope class. |
| 25 | Many small issues fixed. |
| 26 | Create the field in tracing state to store extra info. |
| 27 | Activat dynamic attributes on TracingState and manage a stack per trace. |
| 28 | Build finished. |
| 29 | Change the scope ownership scheme. |
| 30 | Use vector as children container in scope trie. |
| 31 | Avoid segfault in case of memory allocation error. |
| 32 | Changes approved. Finally merged. |
-
William Del Ra, III. 2012. Software systems architecture: second edition by Nick Rozanski and Eoin Woods. SIGSOFT Softw. Eng. Notes 37, 2 (April 2012), 36-36. DOI: https://doi.org/10.1145/2108144.2108171 ↩ ↩2 ↩3
-
Deep Learning with PyTorch by Eli Stevens Luca Antiga. MEAP Publication. https://livebook.manning.com/#!/book/deep-learning-with-pytorch/welcome/v-7/ ↩ ↩2 ↩3
-
PyTorch github website, https://github.com/pytorch/pytorch. ↩ ↩2 ↩3 ↩4 ↩5 ↩6
-
Martín Abadi, Ashish Agarwal, Paul Barham, Eugene Brevdo, Zhifeng Chen, Craig Citro, Greg S. Corrado, Andy Davis, Jeffrey Dean, Matthieu Devin, Sanjay Ghemawat, Ian Goodfellow, Andrew Harp, Geoffrey Irving, Michael Isard, Rafal Jozefowicz, Yangqing Jia, Lukasz Kaiser, Manjunath Kudlur, Josh Levenberg, Dan Mané, Mike Schuster, Rajat Monga, Sherry Moore, Derek Murray, Chris Olah, Jonathon Shlens, Benoit Steiner, Ilya Sutskever, Kunal Talwar, Paul Tucker, Vincent Vanhoucke, Vijay Vasudevan, Fernanda Viégas, Oriol Vinyals, Pete Warden, Martin Wattenberg, Martin Wicke, Yuan Yu, and Xiaoqiang Zheng. TensorFlow: Large-scale machine learning on heterogeneous systems, 2015. Software available from tensorflow.org ↩
-
Y. Jia, E. Shelhamer, J. Donahue, S. Karayev, J. Long, R. Girshick, S. Guadarrama, and T. Darrell. Caffe: Convolutional architecture for fast feature embedding. arXiv:1408.5093>arXiv:1408.5093 2014 ↩
-
Seide, Frank & Agarwal, Amit. (2016). CNTK: Microsoft’s Open-Source Deep-Learning Toolkit. 2135-2135. 10.1145/2939672.2945397. ↩
-
Python-future github website. https://github.com/PythonCharmers/python-future ↩
-
Numpy github website. https://github.com/numpy/numpy ↩
-
Pyyaml github website. https://github.com/yaml/pyyaml ↩
-
Setuptools documentation. https://setuptools.readthedocs.io/en/latest/ ↩
-
Six github website. https://github.com/benjaminp/six ↩
-
Matplotlib github website. https://github.com/matplotlib/matplotlib ↩
-
PyTorch blog. https://pytorch.org/blog/a-tour-of-pytorch-internals-1/ ↩
-
Margaret-Anne Storey, Jody Ryall, R. Ian Bull, Del Myers, Janice Singer, “TODO or To Bug:Exploring How Task Annotations Play a Role in the Work Practices of Software Developers”, InProceedings of the 30th Int’l. Conf. Software Engineering (ICSE ’08), pp. 251-260, 2008. ↩ ↩2
-
A Crystal Ball to Prioritise Technical Debt in Monoliths or Microservices: Adam Tornhill’s Thoughts. https://www.infoq.com/news/2017/04/tornhill-prioritise-tech-debt ↩ ↩2 ↩3
-
Codescene Guides-COMPLEXITY TRENDS https://codescene.io/docs/guides/technical/complexity-trends.html ↩
-
Coupling analysis https://github.com/smontanari/code-forensics/wiki/Coupling-analysis ↩